Image Sensors World Go to the original article...
A team from Google Research has a new blog article on fusing Lidar and camera data for 3D object detection. The motivating problem here seems to be the issue of misalignment between 3D LiDAR data and 2D camera data.The blog discusses the team's forthcoming paper titled "DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection" which will be presented at the IEEE/CVF Computer Vision and Pattern Recognition (CVPR) conference in June 2022. A preprint of the paper is available here.
Some excerpts from the blog and the associated paper:
LiDAR and visual cameras are two types of complementary sensors used for 3D object detection in autonomous vehicles and robots. To develop robust 3D object detection models, most methods need to augment and transform the data from both modalities, making the accurate alignment of the features challenging.
Existing algorithms for fusing LiDAR and camera outputs generally follow two approaches --- input-level fusion where the features are fused at an early stage, decorating points in the LiDAR point cloud with the corresponding camera features, or mid-level fusion where features are extracted from both sensors and then combined. Despite realizing the importance of effective alignment, these methods struggle to efficiently process the common scenario where features are enhanced and aggregated before fusion. This indicates that effectively fusing the signals from both sensors might not be straightforward and remains challenging.

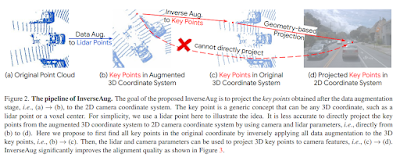
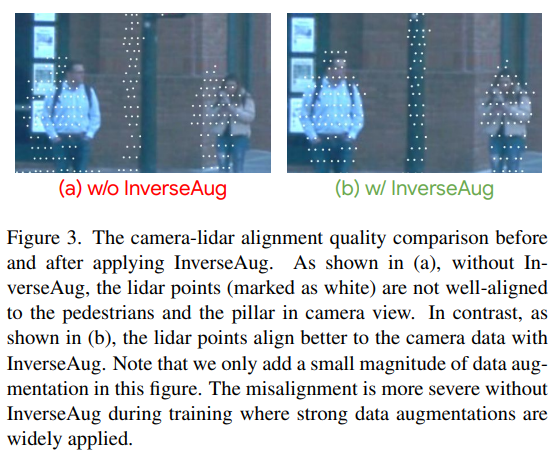
In our CVPR 2022 paper, “DeepFusion: LiDAR-Camera Deep Fusion for Multi-Modal 3D Object Detection”, we introduce a fully end-to-end multi-modal 3D detection framework called DeepFusion that applies a simple yet effective deep-level feature fusion strategy to unify the signals from the two sensing modalities. Unlike conventional approaches that decorate raw LiDAR point clouds with manually selected camera features, our method fuses the deep camera and deep LiDAR features in an end-to-end framework. We begin by describing two novel techniques, InverseAug and LearnableAlign, that improve the quality of feature alignment and are applied to the development of DeepFusion. We then demonstrate state-of-the-art performance by DeepFusion on the Waymo Open Dataset, one of the largest datasets for automotive 3D object detection.
We evaluate DeepFusion on the Waymo Open Dataset, one of the largest 3D detection challenges for autonomous cars, using the Average Precision with Heading (APH) metric under difficulty level 2, the default metric to rank a model’s performance on the leaderboard. Among the 70 participating teams all over the world, the DeepFusion single and ensemble models achieve state-of-the-art performance in their corresponding categories.


Leave a Reply